
计算物理 ›› 2024, Vol. 41 ›› Issue (1): 40-51.DOI: 10.19596/j.cnki.1001-246x.8759
• 面向超级计算机的性能优化技术与数值并行算法专刊 • 上一篇 下一篇
收稿日期:2023-05-15
出版日期:2024-01-25
发布日期:2024-02-05
通讯作者:
翟季冬
作者简介:金煜阳, 男, 博士, 助理研究员, 研究方向为并行应用性能分析与优化、编译技术等, E-mail: jinyuyang@tsinghua.edu.cn
基金资助:
Yuyang JIN( ), Zixuan MA, Jidong ZHAI()
), Zixuan MA, Jidong ZHAI()
Received:2023-05-15
Online:2024-01-25
Published:2024-02-05
Contact:
Jidong ZHAI
摘要:
针对异步策略设计难的问题, 提出面向异构超级计算机的高效异步性能预测方法, 解耦异步与同步执行的性能, 通过层次化建模等技术实现快速精确的性能预测, 指导异步策略设计与性能优化。在国产神威异构高性能计算机上, 以高性能计算领域典型应用为例, 验证所提出建模方法的准确性和高效性。实验结果表明: 本方法平均预测精度达到96.61%, 预测效率在毫秒级。
中图分类号:
金煜阳, 马子轩, 翟季冬. 异步感知的异构高性能计算机性能预测方法[J]. 计算物理, 2024, 41(1): 40-51.
Yuyang JIN, Zixuan MA, Jidong ZHAI. Efficient Asynchronous Performance Prediction for Heterogeneous Systems[J]. Chinese Journal of Computational Physics, 2024, 41(1): 40-51.
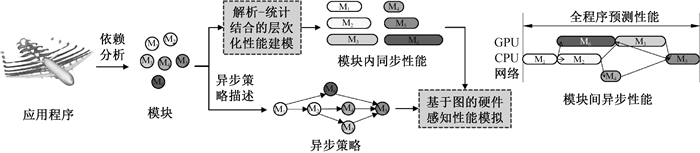
图1 异步策略感知性能预测方法的整体流程
Fig.1 The workflow of the approach of asynchronous strategy-aware performance prediction
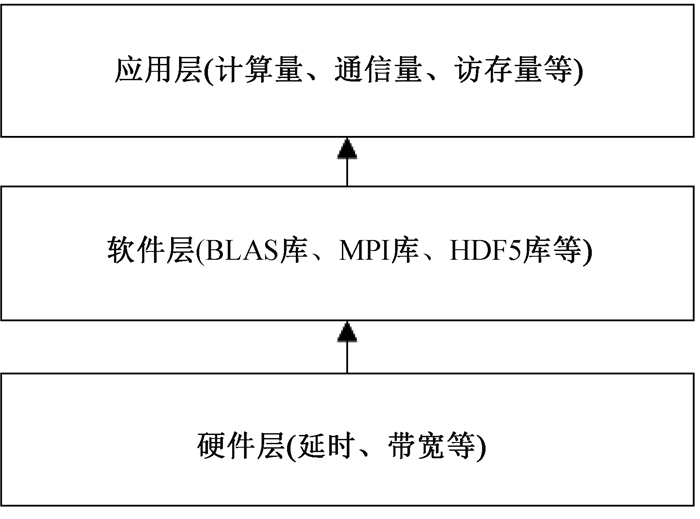
图2 层次化建模
Fig.2 Hierarchical modeling

图3 模拟算法过程示意图 (a) 异步策略示例;(b)模拟过程示意图
Fig.3 Illustration of the simulation process (a) asynchronous strategy example; (b) simulation process
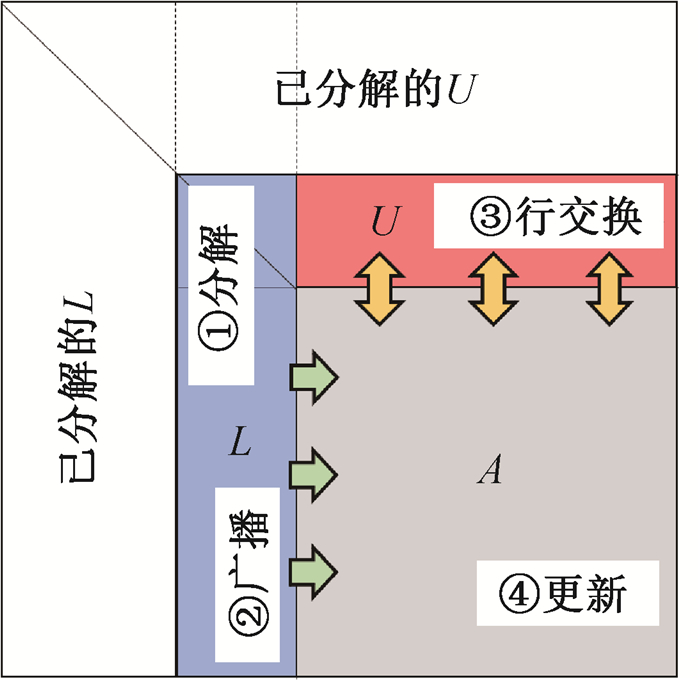
图4 HPL算法示意图
Fig.4 Illustration of HPL algorithm
| 软件参数 | 含义 |
| P | 描述进程网格的行数 |
| Q | 描述进程网格的列数,进程规模应等于P×Q |
| N | 问题规模,表示求解N×N的矩阵 |
| NB | 分块大小,表示将矩阵划分为NB×NB的块矩阵 |
| BCASTs | 广播算法,包括1rg、1rM、2rg、2rM、Lng和LnM算法 |
| SWAP | 行交换算法,包括bin-exch、spreadroll和mix算法 |
| DEPTHs | 前瞻深度(Loop-ahead depth),表示提前进行分解操作的迭代轮数,可以描述不同的异步策略 |
表1 HPL的软件输入参数
Table 1 Input parameters of HPL
| 软件参数 | 含义 |
| P | 描述进程网格的行数 |
| Q | 描述进程网格的列数,进程规模应等于P×Q |
| N | 问题规模,表示求解N×N的矩阵 |
| NB | 分块大小,表示将矩阵划分为NB×NB的块矩阵 |
| BCASTs | 广播算法,包括1rg、1rM、2rg、2rM、Lng和LnM算法 |
| SWAP | 行交换算法,包括bin-exch、spreadroll和mix算法 |
| DEPTHs | 前瞻深度(Loop-ahead depth),表示提前进行分解操作的迭代轮数,可以描述不同的异步策略 |
| 模块 | 应用层关键特征模型 |
| 分解 | 计算量 = mp×NB2 |
| 访存量(mp+NB)×NB | |
| 通信量 = 2NB | |
| 通信次数 = log P | |
| 广播 | 通信量 = mp×NB |
| 行交换 | |
| 更新 | 计算量 = 2×mp×nq×NB |
| 访存量 = 2×mp×NB |
表2 HPL各模块的应用层模型
Table 2 Model of the application layer for HPL modules
| 模块 | 应用层关键特征模型 |
| 分解 | 计算量 = mp×NB2 |
| 访存量(mp+NB)×NB | |
| 通信量 = 2NB | |
| 通信次数 = log P | |
| 广播 | 通信量 = mp×NB |
| 行交换 | |
| 更新 | 计算量 = 2×mp×nq×NB |
| 访存量 = 2×mp×NB |
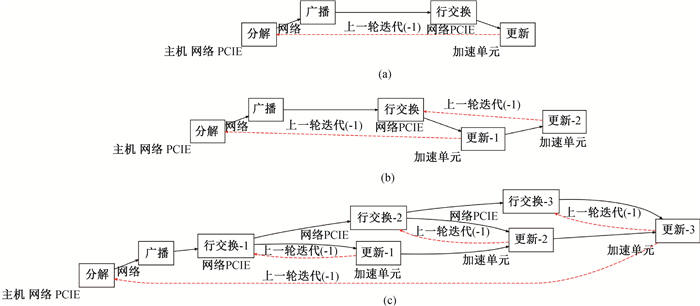
图5 HPL三种策略的有向图 (a)同步策略;(b)更新划分策略;(c)更新+行交换划分策略
Fig.5 Directed graphs of HPL's three strategies (a) a synchronous strategy; (b) "Update" module division strategy; (c) "Update + Row swapping" module division strategy
| 进程规模 | HPL软件输入参数 | 实测结果/% | 预测结果/% | 误差/% | |||
| N | P | Q | NB | ||||
| 32 | 168 960 | 4 | 8 | 384 | 82.78 | 84.40 | 1.96 |
| 256 | 491 520 | 16 | 16 | 384 | 83.31 | 84.26 | 1.14 |
| 1 024 | 970 752 | 32 | 32 | 384 | 82.52 | 83.93 | 1.71 |
| 4 096 | 1 941 504 | 64 | 64 | 384 | 81.06 | 83.65 | 3.20 |
| 16 384 | 3 833 856 | 64 | 256 | 384 | 78.26 | 81.36 | 3.96 |
| 32 768 | 5 505 024 | 128 | 256 | 384 | 79.00 | 83.50 | 5.70 |
| 65 536 | 7 667 712 | 128 | 512 | 384 | 75.34 | 79.90 | 6.05 |
表3 HPL在神威·太湖之光上的预测与实测性能对比
Table 3 Comparison of predicted and measured performance of HPL on Sunway TaihuLight supercomputer
| 进程规模 | HPL软件输入参数 | 实测结果/% | 预测结果/% | 误差/% | |||
| N | P | Q | NB | ||||
| 32 | 168 960 | 4 | 8 | 384 | 82.78 | 84.40 | 1.96 |
| 256 | 491 520 | 16 | 16 | 384 | 83.31 | 84.26 | 1.14 |
| 1 024 | 970 752 | 32 | 32 | 384 | 82.52 | 83.93 | 1.71 |
| 4 096 | 1 941 504 | 64 | 64 | 384 | 81.06 | 83.65 | 3.20 |
| 16 384 | 3 833 856 | 64 | 256 | 384 | 78.26 | 81.36 | 3.96 |
| 32 768 | 5 505 024 | 128 | 256 | 384 | 79.00 | 83.50 | 5.70 |
| 65 536 | 7 667 712 | 128 | 512 | 384 | 75.34 | 79.90 | 6.05 |
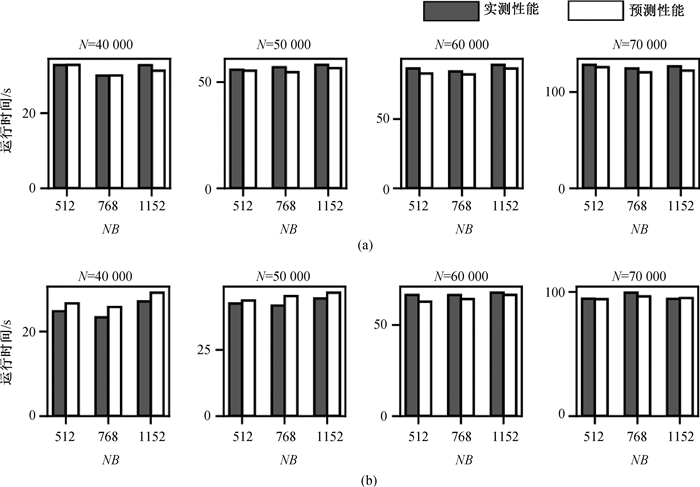
图6 HPL在Gorgon上的预测与实测性能 (a)同步策略;(b)更新划分策略
Fig.6 Predicted and measured performances of HPL on Gorgon cluster (a) a synchronous strategy; (b) "Update" module division strategy
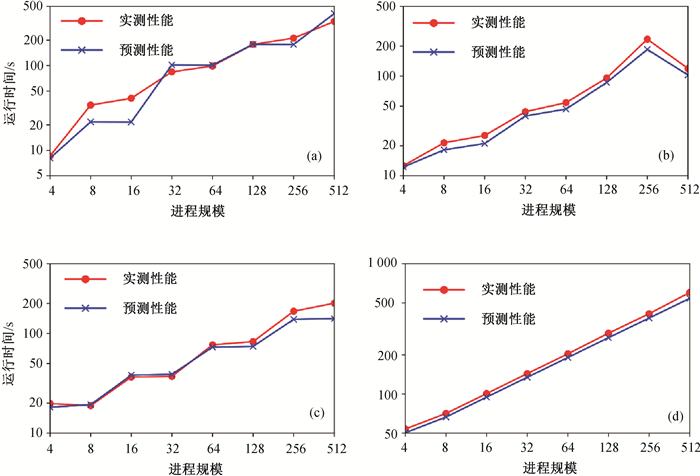
图7 HPL模块内预测与实测性能(a)广播模块;(b)分解模块;(c)行交换模块;(d)更新模块
Fig.7 Predicted and measured performances of HPL modules (a) "Broadcast" module; (b) "Panel factorization" module; (c) "Row swapping" module; (d) "Update" module
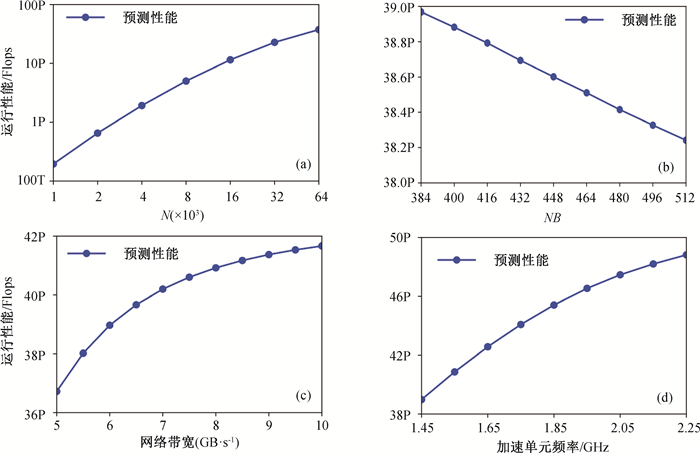
图8 假设分析预测结果
Fig.8 The prediction results of what-if analysis
| 进程规模 | 32 | 256 | 1 024 | 4 096 | 16 384 | 32 768 | 65 536 |
| 同步策略 | 0.27 | 0.44 | 0.85 | 1.57 | 3.25 | 6.73 | 13.21 |
| 更新划分策略 | 0.33 | 0.83 | 1.46 | 2.68 | 5.13 | 9.73 | 17.63 |
| 更新+行交换划分策略 | 0.63 | 0.97 | 2.01 | 3.17 | 5.77 | 11.31 | 19.24 |
表4 模拟算法的运行时间(ms)
Table 4 The execution time of simulation algorithm (ms)
| 进程规模 | 32 | 256 | 1 024 | 4 096 | 16 384 | 32 768 | 65 536 |
| 同步策略 | 0.27 | 0.44 | 0.85 | 1.57 | 3.25 | 6.73 | 13.21 |
| 更新划分策略 | 0.33 | 0.83 | 1.46 | 2.68 | 5.13 | 9.73 | 17.63 |
| 更新+行交换划分策略 | 0.63 | 0.97 | 2.01 | 3.17 | 5.77 | 11.31 | 19.24 |
| 1 | DONGARRA J J , MEUER H W , STROHMAIER E . TOP500 supercomputer sites[J]. Supercomputer, 1997, 13 (1): 89- 111. |
| 2 | YASHIRO H, TERAI M, YOSHIDA R, et al. Performance analysis and optimization of nonhydrostatic icosahedral atmospheric model (NICAM) on the K computer and TSUBAME2.5[C]//Proceedings of the Platform for Advanced Scientific Computing Conference. Lausanne, Switzerland: Association for Computing Machinery, 2016: 1-8. |
| 3 | 徐小文, 莫则尧, 武林平. 迭代方法中基于渐近规模的通信与计算比分析[J]. 计算机学报, 2013, 36 (4): 782- 789. |
| 4 | 任健, 武林平, 申卫东. 基于JASMIN框架多物理耦合程序的性能优化及分析[J]. 计算物理, 2015, 32 (4): 431- 436. |
| 5 |
范宣华, 王柯颖, 肖世富, 等. 强脉动压力下飞行器随机振动分析算法与并行实现[J]. 计算物理, 2021, 38 (2): 192- 198.
DOI |
| 6 |
于晨阳, 范宣华, 王柯颖, 等. 基于PANDA平台的多点基础激励谐响应的并行计算[J]. 计算物理, 2018, 35 (4): 443- 450.
DOI |
| 7 | 水超洋, 于献智, 王银山, 等. 国产异构系统上HPL的优化与分析[J]. 软件学报, 2021, 32 (8): 2319- 2328. |
| 8 | 刘芳芳, 王志军, 汪荃, 等. 国产异构系统上的HPCG并行算法及高效实现[J]. 软件学报, 2021, 32 (8): 2341- 2351. |
| 9 | AO Yulong, YANG Chao, WANG Xinliang, et al. 26 PFLOPS stencil computations for atmospheric modeling on sunway TaihuLight[C]//2017 IEEE International Parallel and Distributed Processing Symposium (IPDPS). Orlando, FL, USA: IEEE, 2017: 535-544. |
| 10 |
蔡颖, 张存波, 刘旭, 等. 二维球坐标系中子输运方程的一种并行SN算法[J]. 计算物理, 2022, 39 (2): 143- 152.
DOI |
| 11 | MICIKEVICIUS P. 3D finite difference computation on GPUs using CUDA[C]//Proceedings of 2nd workshop on general purpose processing on graphics processing units. Washington, D.C., USA: Association for Computing Machinery, 2009: 79-84. |
| 12 | ZHANG Hao, ZHENG Zeyu, XU Shizhen, et al. Poseidon: an efficient communication architecture for distributed deep learning on GPU clusters[C]//Proceedings of the 2017 USENIX Conference on USENIX Annual Technical Conference. Santa Clara, CA, USA: USENIX Association, 2017: 181-193. |
| 13 | CULLER D, KARP R, PATTERSON D, et al. LogP: Towards a realistic model of parallel computation[C]//Proceedings of the fourth ACM SIGPLAN symposium on Principles and practice of parallel programming. San Diego, California, USA: Association for Computing Machinery, 1993: 1-12. |
| 14 | BARNES B J, ROUNTREE B, LOWENTHAL D K, et al. A regression-based approach to scalability prediction[C]//Proceedings of the 22nd annual international conference on Supercomputing. Island of Kos, Greece: Association for Computing Machinery, 2008: 368-377. |
| 15 | BHATTACHARYYA A, HOEFLER T. PEMOGEN: Automatic adaptive performance modeling during program runtime[C]//2014 23rd International Conference on Parallel Architecture and Compilation Techniques (PACT). Edmonton, AB, Canada: IEEE, 2014: 393-404. |
| 16 | RODRIGUES A F , HEMMERT K S , BARRETT B W , et al. The structural simulation toolkit[J]. ACM SIGMETRICS Performance Evaluation Review, 2011, 38 (4): 37- 42. |
| 17 | CASANOVA H. Simgrid: A toolkit for the simulation of application scheduling[C]//Proceedings First IEEE/ACM International Symposium on Cluster Computing and the Grid. Brisbane, QLD, Australia: IEEE, 2001: 430-437. |
| 18 | ZHAI Jidong , CHEN Wenguang , ZHENG Weimin . PHANTOM: Predicting performance of parallel applications on large-scale parallel machines using a single node[J]. ACM Sigplan Notices, 2010, 45 (5): 305- 314. |
| 19 | JIN Yuyang, WANG Haojie, ZHONG Runxin, et al. PerFlow: A domain specific framework for automatic performance analysis of parallel applications[C]//Proceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. Seoul, Republic of Korea: Association for Computing Machinery, 2022: 177-191. |
| 20 | DONGARRA J J , LUSZCZEK P , PETITET A . The LINPACK benchmark: Past, present and future[J]. Concurrency and Computation: Practice and Experience, 2003, 15 (9): 803- 820. |
| 21 | CALOTOIU A, BECKINSALE D, EARL C W, et al. Fast multi-parameter performance modeling[C]//2016 IEEE International Conference on Cluster Computing (CLUSTER). Taipei, Taiwan: IEEE, 2016: 172-181. |
| 22 | GABRIEL E, FAGG G E, BOSILCA G, et al. Open MPI: Goals, concept, and design of a next generation MPI implementation[C]//Recent Advances in Parallel Virtual Machine and Message Passing Interface: 11th European PVM/MPI Users' Group Meeting. Budapest, Hungary: Springer, 2004: 97-104. |
| 23 | THAKUR R , RABENSEIFNER R , GROPP W . Optimization of collective communication operations in MPICH[J]. The International Journal of High Performance Computing Applications, 2005, 19 (1): 49- 66. |
| 24 | BAR-NOY A, KIPNIS S. Designing broadcasting algorithms in the postal model for message-passing systems[C]//Proceedings of the fourth annual ACM symposium on Parallel algorithms and architectures. San Diego, California, USA: Association for Computing Machinery, 1992: 13-22. |
| 25 | ELLER P R, HOEFLER T, GROPP W. Using performance models to understand scalable Krylov solver performance at scale for structured grid problems[C]//Proceedings of the ACM International Conference on Supercomputing. Phoenix, Arizona: Association for Computing Machinery, 2019: 138-149. |
| [1] | 莫则尧, 王龙, 刘杰, 谭光明, 刘伟峰, 喻之斌, 翟季冬, 杨海龙, 徐小文. 围炉对谈: 性能优化的个性与共性[J]. 计算物理, 2024, 41(1): 3-8. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
版权所有 © 《计算物理》编辑部
地址:北京市海淀区丰豪东路2号 邮编:100094 E-mail:jswl@iapcm.ac.cn
本系统由北京玛格泰克科技发展有限公司设计开发