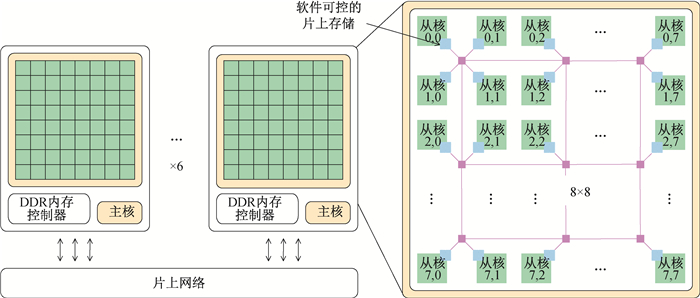
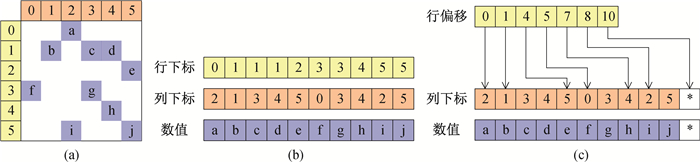
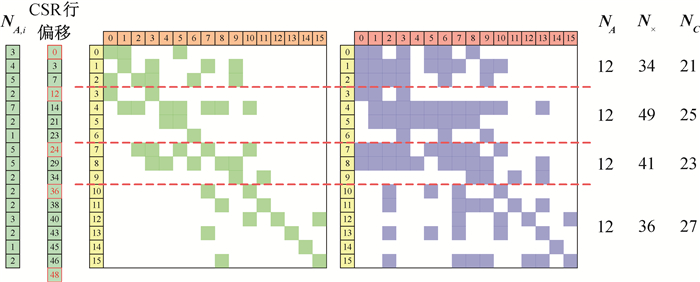
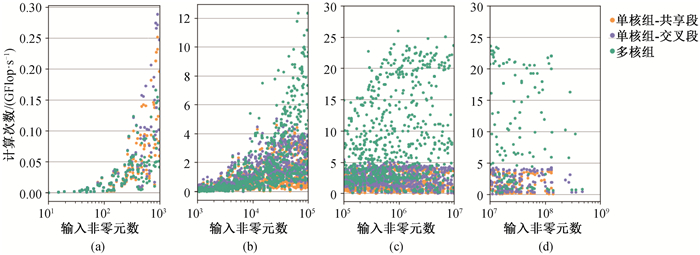
| 1 |
BAKER A H, GAMBLIN T, SCHULZ M, et al. Challenges of scaling algebraic multigrid across modern multicore architectures[C]//2011 IEEE International Parallel & Distributed Processing Symposium. Anchorage, AK, USA: IEEE, 2011: 275-286.
|
| 2 |
BELL N , DALTON S , OLSON L N . Exposing fine-grained parallelism in algebraic multigrid methods[J]. SIAM Journal on Scientific Computing, 2012, 34 (4): C123- C152.
DOI
|
| 3 |
BALLARD G , SIEFERT C , HU J . Reducing communication costs for sparse matrix multiplication within algebraic multigrid[J]. SIAM Journal on Scientific Computing, 2016, 38 (3): C203- C231.
DOI
|
| 4 |
XU Xiaowen , YUE Xiaoqiang , MAO Runzhang , et al. JXPAMG: A parallel algebraic multigrid solver for extreme-scale numerical simulations[J]. CCF Transactions on High Performance Computing, 2023, 5 (1): 72- 83.
DOI
|
| 5 |
MULLOWNEY P, LI Ruipeng, THOMAS S, et al. Preparing an incompressible-flow fluid dynamics code for exascale-class wind energy simulations[C]//Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. St. Louis, Missouri: Association for Computing Machinery, 2021: 1-16.
|
| 6 |
TIAN Rong , ZHOU Mozhen , WANG Jingtao , et al. A challenging dam structural analysis: large-scale implicit thermo-mechanical coupled contact simulation on Tianhe-Ⅱ[J]. Computational Mechanics, 2019, 63 (1): 99- 119.
DOI
|
| 7 |
GILBERT J R , MOLER C , SCHREIBER R . Sparse matrices in MATLAB: Design and implementation[J]. SIAM Journal on Matrix Analysis and Applications, 1992, 13 (1): 333- 356.
DOI
|
| 8 |
DEMOUTH J. Sparse matrix-matrix multiplication on the GPU[C]. NVIDIA GPU Technology Conference. San Jose, CA: NVIDIA, 2012.
|
| 9 |
ANH P N Q, FAN Rui, WEN Yonggang. Balanced hashing and efficient GPU sparse general matrix-matrix multiplication[C]//Proceedings of the 2016 International Conference on Supercomputing. Istanbul, Turkey: Association for Computing Machinery, 2016: 1-12.
|
| 10 |
NAGASAKA Yu sue, NUKADA A, MATSUOKA S. High-performance and memory-saving sparse general matrix-matrix multiplication for NVIDIA pascal GPU[C]//2017 46th International Conference on Parallel Processing (ICPP). Bristol, UK: IEEE, 2017: 101-110.
|
| 11 |
DEVECI M, TROTT C, RAJAMANICKAM S. Performance-portable sparse matrix-matrix multiplication for many-core architectures[C]//2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). Lake Buena Vista, FL, USA: IEEE, 2017: 693-702.
|
| 12 |
PARGER M, WINTER M, MLAKAR D, et al. SpECK: Accelerating GPU sparse matrix-matrix multiplication through lightweight analysis[C]//Proceedings of the 25th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. San Diego, California: Association for Computing Machinery, 2020: 362-375.
|
| 13 |
DALTON S, BAXTER S, MERRILL D, et al. Optimizing sparse matrix operations on GPUs using merge path[C]//2015 IEEE International Parallel and Distributed Processing Symposium. Hyderabad, India: IEEE, 2015: 407-416.
|
| 14 |
MERRILL D. CUB: CUDA unbound, a library of warp-wide, block-wide, and device-wide GPU parallel primitives[Z]. 2015.
|
| 15 |
HOU Kaixi, LIU Weifeng, WANG Hao, et al. Fast segmented sort on GPUs[C]//Proceedings of the International Conference on Supercomputing. Chicago, Illinois: Association for Computing Machinery, 2017: 1-10.
|
| 16 |
JI Haonan , LU Shibo , HOU Kaixi , et al. Segmented merge: A new primitive for parallel sparse matrix computations[J]. International Journal of Parallel Programming, 2021, 49 (5): 732- 744.
DOI
|
| 17 |
DALTON S , OLSON L , BELL N . Optimizing sparse matrix-matrix multiplication for the GPU[J]. ACM Transactions on Mathematical Software, 2015, 41 (4): 1- 20.
|
| 18 |
LIU Weifeng, VINTER B. An efficient GPU general sparse matrix-matrix multiplication for irregular data[C]//2014 IEEE 28th International Parallel and Distributed Processing Symposium. Phoenix, AZ, USA: IEEE, 2014: 370-381.
|
| 19 |
GREMSE F , HÖFTER A , SCHWEN L O , et al. GPU-accelerated sparse matrix-matrix multiplication by iterative row merging[J]. SIAM Journal on Scientific Computing, 2015, 37 (1): C54- C71.
DOI
|
| 20 |
WINTER M, MLAKAR D, ZAYER R, et al. Adaptive sparse matrix-matrix multiplication on the GPU[C]//Proceedings of the 24th Symposium on Principles and Practice of Parallel Programming. Washington, District of Columbia: Association for Computing Machinery, 2019: 68-81.
|
| 21 |
XIE Zhen, TAN Guangming, LIU Weifeng, et al. IA-SpGEMM: An input-aware auto-tuning framework for parallel sparse matrix-matrix multiplication[C]//Proceedings of the ACM International Conference on Supercomputing. Phoenix, Arizona: Association for Computing Machinery, 2019: 94-105.
|
| 22 |
ZHANG Jianting, GRUENWALD L. Regularizing irregularity: Bitmap-based and portable sparse matrix multiplication for graph data on GPUs[C]//Proceedings of the 1st ACM SIGMOD Joint International Workshop on Graph Data Management Experiences & Systems (GRADES) and Network Data Analytics (NDA). Houston, Texas: Association for Computing Machinery, 2018: 1-8.
|
| 23 |
NIU Yuyao, LU Zhengyang, JI Haonan, et al. TileSpGEMM: A tiled algorithm for parallel sparse general matrix-matrix multiplication on GPUs[C]//Proceedings of the 27th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. Seoul, Republic of Korea: Association for Computing Machinery, 2022: 90-106.
|
| 24 |
INOUE H, MORIYAMA T, KOMATSU H, et al. AA-Sort: A new parallel sorting algorithm for multi-core SIMD processors[C]//16th International Conference on Parallel Architecture and Compilation Techniques (PACT 2007). Brasov, Romania: IEEE, 2007: 189-198.
|
| 25 |
CHHUANI J , NGUYEN A D , LEE V W , et al. Efficient implementation of sorting on multi-core SIMD CPU architecture[J]. Proceedings of the VLDB Endowment, 2008, 1 (2): 1313- 1324.
DOI
|
 ), Lei YANG2, Wei XUE1,*(
), Lei YANG2, Wei XUE1,*(