
计算物理 ›› 2024, Vol. 41 ›› Issue (1): 52-63.DOI: 10.19596/j.cnki.1001-246x.8777
• 面向超级计算机的性能优化技术与数值并行算法专刊 • 上一篇 下一篇
张鹏1,2( ), 张爱清1,2,*(), 莫则尧1,3, 王景焘1,2
), 张爱清1,2,*(), 莫则尧1,3, 王景焘1,2
收稿日期:2023-06-09
出版日期:2024-01-25
发布日期:2024-02-05
通讯作者:
张爱清
作者简介:张鹏, 男, 博士, 副研究员, 研究方向为高性能计算、数值软件性能优化, E-mail: zhang_peng@iapcm.ac.cn
Peng ZHANG1,2(), Aiqing ZHANG1,2,*(), Zeyao MO1,3, Jingtao WANG1,2
Received:2023-06-09
Online:2024-01-25
Published:2024-02-05
Contact:
Aiqing ZHANG
摘要:
针对手工软件性能优化缺乏可复用性和可移植性的问题, 设计实现一种面向实际数值模拟软件的跨平台自动性能优化编程工具SEMD (Single element-based computing multiple data)。SEMD采用数值模拟领域基于网格的高层语义对数值计算循环进行抽象, 完全屏蔽底层硬件特征和性能优化实现, 使得基于其编写的数值计算子程序能够自动实现跨平台性能可移植。典型算例测试结果显示: 在X86、ARM、GPU三种不同架构的处理器上, SEMD的整体性能优化效果超过国际上的同类产品。此外, SEMD在结构、流体、电磁等领域实际数值模拟软件的研制中也得到了初步应用, 支撑4款软件热点数值计算子程序平均性能提升164%.
中图分类号:
张鹏, 张爱清, 莫则尧, 王景焘. SEMD:一种面向实际数值模拟软件的跨平台自动性能优化编程工具[J]. 计算物理, 2024, 41(1): 52-63.
Peng ZHANG, Aiqing ZHANG, Zeyao MO, Jingtao WANG. SEMD: A Cross-platform Automatic Performance Optimization Programming Tool for Real Numerical Simulation Software[J]. Chinese Journal of Computational Physics, 2024, 41(1): 52-63.
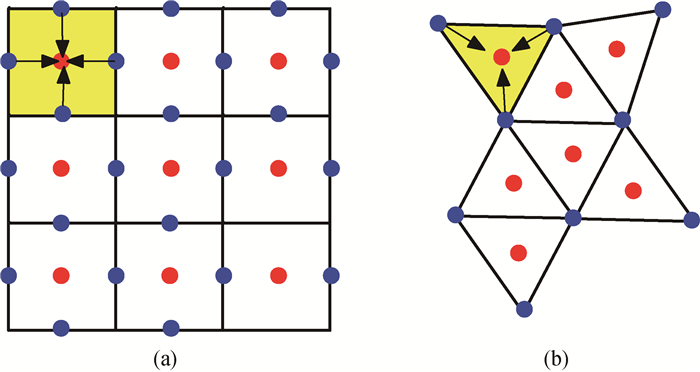
图1 SEMD计算模式示意图 (a)结构网格;(b)非结构网格
Fig.1 Schematic diagram of SEMD computing pattern (a) grid structure; (b)non-grid structure
| 概念 | 含义 |
| 离散实体 | 网格单元上的离散位置,分为单元中心(Cell), 单元结点(Node), 单元棱心(Edge)等不同类型 |
| 实体集 | 由相同类型的离散实体构成的集合 |
| 场量 | 与离散实体分布相关的数据量,如物理场、网格坐标场等 |
| 参量 | 与离散实体分布无关的数据量,如物理参数等 |
| 单元计算格式 | 单次循环迭代内,场量与参量间的数值计算序列 |
表1 SEMD接口相关的概念定义
Table 1 Conceptual definitions related to the SEMD interface
| 概念 | 含义 |
| 离散实体 | 网格单元上的离散位置,分为单元中心(Cell), 单元结点(Node), 单元棱心(Edge)等不同类型 |
| 实体集 | 由相同类型的离散实体构成的集合 |
| 场量 | 与离散实体分布相关的数据量,如物理场、网格坐标场等 |
| 参量 | 与离散实体分布无关的数据量,如物理参数等 |
| 单元计算格式 | 单次循环迭代内,场量与参量间的数值计算序列 |
| 接口名称 | 接口定义形式 |
| 场量 | FieldData<属性…>(参数…) 属性:数据类型、实体集类型、内存布局方式、内存管理方式 参数:内存地址、实体集 |
| 参量 | ParamData<属性…>(参数…) 属性:数据类型、内存布局方式、内存管理方式 参数:索引范围、内存地址 |
| 实体集 | EntitySet<属性…>(参数…) 属性:实体类型、索引空间类型、网格类型 参数:索引空间、网格 |
表2 SEMD主要数据接口的定义形式
Table 2 Definition format for primary data interface of SEMD
| 接口名称 | 接口定义形式 |
| 场量 | FieldData<属性…>(参数…) 属性:数据类型、实体集类型、内存布局方式、内存管理方式 参数:内存地址、实体集 |
| 参量 | ParamData<属性…>(参数…) 属性:数据类型、内存布局方式、内存管理方式 参数:索引范围、内存地址 |
| 实体集 | EntitySet<属性…>(参数…) 属性:实体类型、索引空间类型、网格类型 参数:索引空间、网格 |

图2 SEMD define_e_subroutine接口示例
Fig.2 Example of SEMD define_e_subroutine interface

图3 SEMD call_e_subroutine接口示例
Fig.3 Example of SEMD call_e_subroutine interface
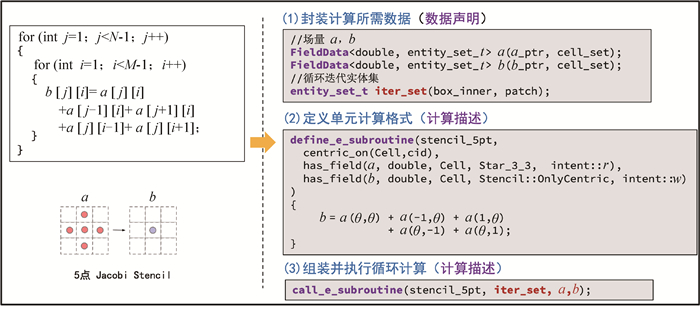
图4 SEMD接口编程示例: 5点Jacobi-stencil循环
Fig.4 Programming example of SEMD interface: 5 point Jacobi-stencil loop
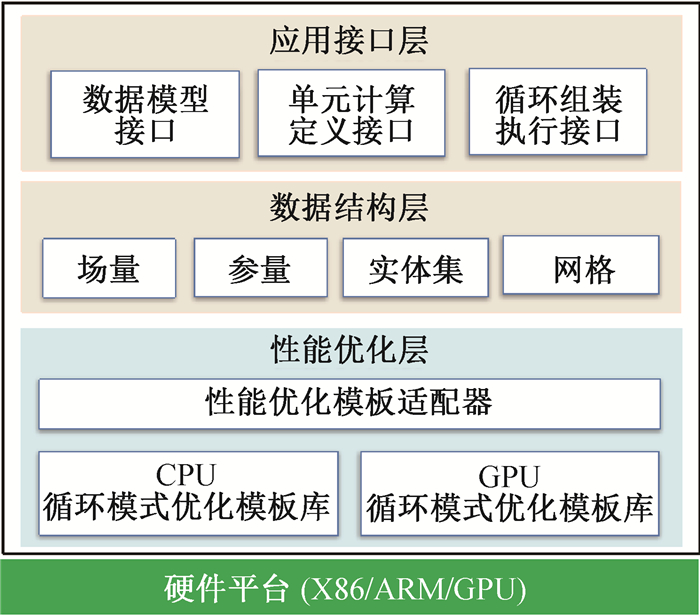
图5 SEMD软件体系结构图
Fig.5 The software architecture of SEMD
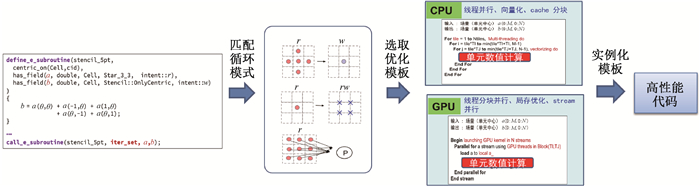
图6 SEMD自动性能优化工作流程图
Fig.6 SEMD automatic performance optimization workflow diagram
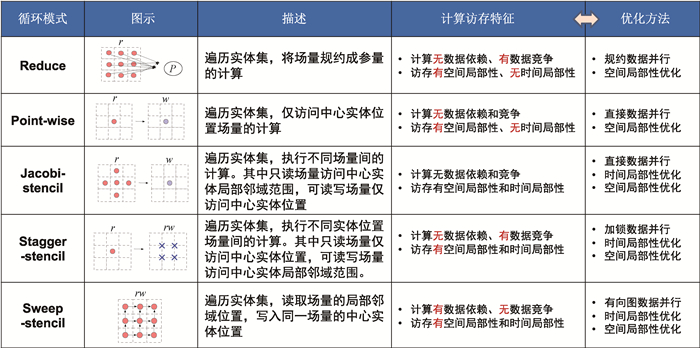
图7 基于“计算-访存”特征的循环模式分类
Fig.7 Classification of loop patterns based on "Compute-Memory Access" characteristics
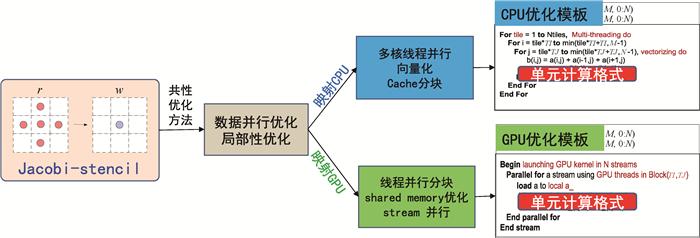
图8 Jacobi-stencil模式的性能优化模板定制过程示意图
Fig.8 Schematic diagram of customization process for performance optimization template of Jacobi-stencil pattern
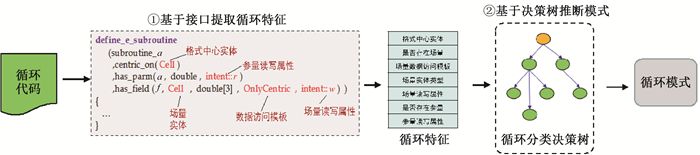
图9 循环模式自动适配机制
Fig.9 Automatic adaptation mechanism of loop patterns
| 算例 | 网格计算规模 | ||
| CPU(串行) | CPU(并行) | GPU | |
| Jacobi2D | 1 000×1 000 | 2 000×2 000 | 2 000×2 000 |
| Heat2D | 1 000×1 000 | 2 000×2 000 | 2 000×2 000 |
| Pointwise3D | 100×100×100 | 200×200×200 | 200×200×200 |
| Jacobi3D | 100×100×100 | 200×200×200 | 200×200×200 |
| Heat3D | 100×100×100 | 200×200×200 | 200×200×200 |
表3 测试算例在不同平台上的计算规模
Table 3 The computational scale of the test cases varies across different platforms
| 算例 | 网格计算规模 | ||
| CPU(串行) | CPU(并行) | GPU | |
| Jacobi2D | 1 000×1 000 | 2 000×2 000 | 2 000×2 000 |
| Heat2D | 1 000×1 000 | 2 000×2 000 | 2 000×2 000 |
| Pointwise3D | 100×100×100 | 200×200×200 | 200×200×200 |
| Jacobi3D | 100×100×100 | 200×200×200 | 200×200×200 |
| Heat3D | 100×100×100 | 200×200×200 | 200×200×200 |
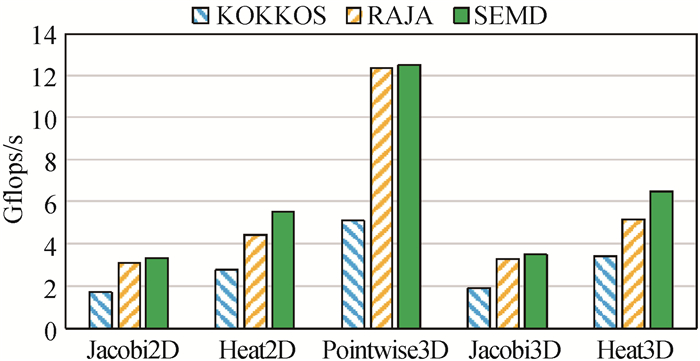
图10 SEMD与Kokkos、RAJA在X86处理器上的串行性能测试结果
Fig.10 Serial performance results of SEMD and Kokkos, RAJA on X86 CPU
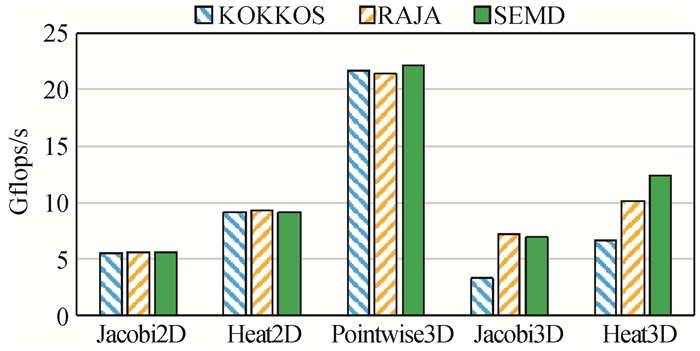
图11 SEMD与Kokkos、RAJA在X86处理器上的并行性能测试结果(12核)
Fig.11 Parallel performance results of SEMD and Kokkos, RAJA on X86 CPU(12 Cores)
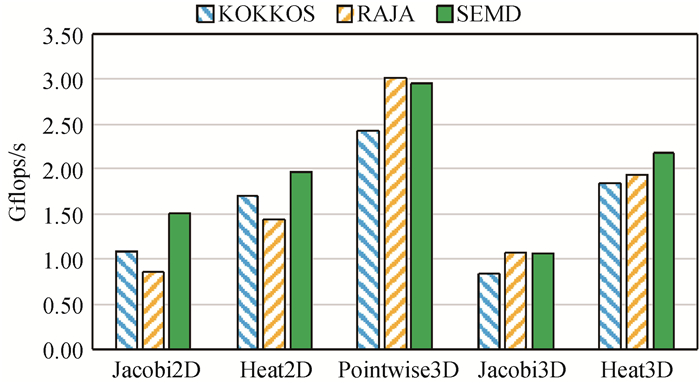
图12 SEMD与Kokkos、RAJA在ARM处理器上的串行性能测试结果
Fig.12 Serial performance results of SEMD and Kokkos, RAJA on ARM CPU
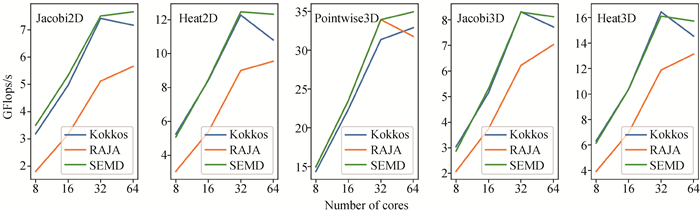
图13 SEMD与Kokkos、RAJA在ARM处理器上并行可扩展性的测试结果
Fig.13 Parallel scaling results of SEMD and Kokkos, RAJA on ARM CPU
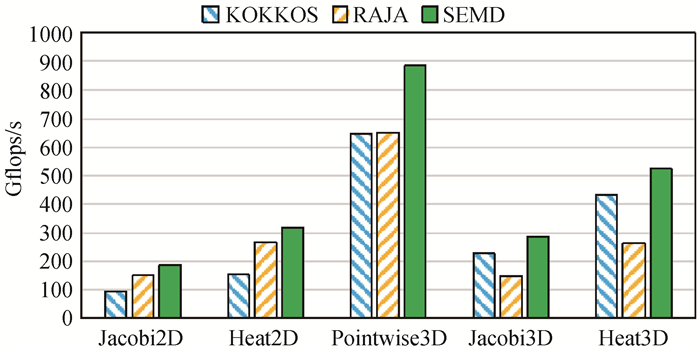
图14 SEMD与Kokkos、RAJA在GPU平台上的性能测试结果
Fig.14 Performance results of SEMD and Kokkos, RAJA on GPU
| 1 |
MO Zeyao , ZHANG Aiqing , CAO Xiaolin , et al. JASMIN: A parallel software infrastructure for scientific computing[J]. Frontiers of Computer Science in China, 2010, 4 (4): 480- 488.
DOI |
| 2 |
任健, 武林平, 申卫东. 基于JASMIN框架多物理耦合程序的性能优化及分析[J]. 计算物理, 2015, 32 (4): 431- 436.
DOI |
| 3 | 程汤培, 莫则尧, 邵景力. 基于JASMIN的地下水流大规模并行数值模拟[J]. 计算物理, 2013, 30 (3): 317- 325. |
| 4 | 郭红, 曹小林, 胡晓燕. 基于JASMIN框架的FFT并行解法器及其应用[J]. 计算物理, 2011, 28 (4): 475- 480. |
| 5 | LIU Qingkai, ZHAO Weibo, CHENG Jie, et al. A programming framework for large scale numerical simulations on unstructured mesh[C]//2016 IEEE 2nd International Conference on Big Data Security on Cloud (BigDataSecurity), IEEE International Conference on High Performance and Smart Computing (HPSC), and IEEE International Conference on Intelligent Data and Security (IDS). New York, NY, USA: IEEE, 2016: 310-315. |
| 6 | WISSINK A M, HORNUNG R D, KOHN S R, et al. Large scale parallel structured AMR calculations using the SAMRAI framework[C]//SC '01: Proceedings of the 2001 ACM/IEEE Conference on Supercomputing. Denver, CO, USA: IEEE, 2001: 22-22. |
| 7 | TOP500. org. Top500 list[EB/OL]. [2023-05-10]. https://www.top500.org/lists/top500/2023/06/. |
| 8 |
CARTER EDWARDS H , TROTT C R , SUNDERLAND D . Kokkos: Enabling manycore performance portability through polymorphic memory access patterns[J]. Journal of Parallel and Distributed Computing, 2014, 74 (12): 3202- 3216.
DOI |
| 9 | REGULY I Z, MUDALIGE G R, GILES M B, et al. The OPS domain specific abstraction for multi-block structured grid computations[C]//2014 Fourth International Workshop on Domain-Specific Languages and High-Level Frameworks for High Performance Computing. New Orleans, LA, USA: IEEE, 2014: 58-67. |
| 10 | BONDHUGULA U, HARTONO A, RAMANUJAM J, et al. A practical automatic polyhedral parallelizer and locality optimizer[C]//Proceedings of the 29th ACM SIGPLAN Conference on Programming Language Design and Implementation. Tucson, AZ, USA: Association for Computing Machinery, 2008: 101-113. |
| 11 | BECKINGSALE D A, BURMARK J, HORNUNG R, et al. RAJA: Portable performance for Large-scale scientific applications[C]//2019 IEEE/ACM International Workshop on Performance, Portability and Productivity in HPC (P3HPC). Denver, CO, USA: IEEE, 2019: 71-81. |
| 12 | TANG Yuan, CHOWDHURY R A, KUSZMAUL B C, et al. The pochoir stencil compiler[C]//Proceedings of the Twenty-third Annual ACM Symposium on Parallelism in Algorithms and Architectures. San Jose, California, USA: Association for Computing Machinery, 2011: 117-128. |
| 13 | TANG Yuan, CHOWDHURY R A, LUK C K, et al. Coding stencil computations using the pochoir stencil-specification language[C]. Proceedings of the 3rd USENIX Workshop on Hot Topics in Parallelism (HotPar 2011). Berkeley, California: USENIX Association, 2011. |
| 14 | HENRETTY T, VERAS R, FRANCHETT F, et al. A stencil compiler for short-vector SIMD architectures[C]//Proceedings of the 27th International ACM Conference on International Conference on Supercomputing. Eugene, Oregon, USA: Association for Computing Machinery, 2013: 13-24. |
| 15 | INTEL C. Intel cilk plus language specification[EB/OL]. [2023-05-11]. http://software.intel.com/sites/products/cilk-plus. |
| 16 | HENRETTY T, STOCK K, POUCHET L N, et al. Data layout transformation for stencil computations on short-vector SIMD architectures[C]//International Conference on Compiler Construction-CC 2011: Compiler Construction. Saarbrücken, Germany: Springer, 2011: 225-245. |
| 17 | CHRISTEN M, SCHENK O, BURKHART H. PATUS: A code generation and autotuning framework for parallel iterative stencil computations on modern microarchitectures[C]//2011 IEEE International Parallel & Distributed Processing Symposium. Anchorage, AK, USA: IEEE, 2011: 676-687. |
| 18 | MUDALIGE G R, GILES M B, REGULY I, et al. OP2: An active library framework for solving unstructured mesh-based applications on multi-core and many-core architectures[C]//2012 Innovative Parallel Computing (InPar). San Jose, CA, USA: IEEE, 2012: 1-12. |
| 19 | ACHARYA A, BONDHUGULA U. Pluto+: Near-complete modeling of affine transformations for parallelism and locality[C]//Proceedings of the 20th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. San Francisco, CA, USA: Association for Computing Machinery, 2015: 54-64. |
| 20 | CAAMAÑO J M M, SUKUMARAN-RAJAM A, BALOIAN A, et al. APOLLO: Automatic speculative polyhedral loop optimizer[C]//IMPACT 2017-7th International Workshop on Polyhedral Compilation Techniques. Stockholm, Sweden: HAL, 2017: hal-01533692. |
| 21 | RAGAN-KELLEY J, BARNES C, ADAMS A, et al. Halide: A language and compiler for optimizing parallelism, locality, and recomputation in image processing pipelines[C]//Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation. Seattle, Washington, USA: Association for Computing Machinery, 2013: 519-530. |
| 22 | RAGAN-KELLEY J , ADAMS A , PARIS S , et al. Decoupling algorithms from schedules for easy optimization of image processing pipelines[J]. ACM Transactions on Graphics, 2012, 31 (4): 32. |
| 23 | 卢兴敬, 刘雷, 贾海鹏, 等. ParaC: 面向GPU平台的图像处理领域的编程框架[J]. 软件学报, 2017, 28 (7): 1655- 1675. |
| 24 | STONE J E , GOHARA D , SHI Guochun . OpenCL: A parallel programming standard for heterogeneous computing systems[J]. Computing in Science & Engineering, 2010, 12 (3): 66- 72. |
| 25 | ECP. Overview of the ECP[EB/OL]. [2023-05-11]. https://www.exascaleproject.org/about. |
| 26 | 赵捷, 李颖颖, 赵荣彩. 基于多面体模型的编译"黑魔法"[J]. 软件学报, 2018, 29 (8): 2371- 2396. |
| No related articles found! |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
版权所有 © 《计算物理》编辑部
地址:北京市海淀区丰豪东路2号 邮编:100094 E-mail:jswl@iapcm.ac.cn
本系统由北京玛格泰克科技发展有限公司设计开发