
Chinese Journal of Computational Physics ›› 2024, Vol. 41 ›› Issue (1): 9-21.DOI: 10.19596/j.cnki.1001-246x.8784
• Performance Optimization Techniques and Parallel Numerical Algorithms for Supercomputing • Previous Articles Next Articles
Jie LIU1,2( ), Yongzhen SHI1,2, Bo YANG1, Xiang ZHANG1, Xinhai CHEN1, Huajian ZHANG1,2, Xiaowei GUO1, Shengguo LI1, Runhua LI1,2, Jintao PENG1,2, Tiaojie XIAO1, Xuguang CHEN1, Qingyang ZHANG1, Biao LI1,2, Can LENG1,2, Yushui LI1,2, Qinglin WANG1,2,*()
), Yongzhen SHI1,2, Bo YANG1, Xiang ZHANG1, Xinhai CHEN1, Huajian ZHANG1,2, Xiaowei GUO1, Shengguo LI1, Runhua LI1,2, Jintao PENG1,2, Tiaojie XIAO1, Xuguang CHEN1, Qingyang ZHANG1, Biao LI1,2, Can LENG1,2, Yushui LI1,2, Qinglin WANG1,2,*()
Received:2023-06-27
Online:2024-01-25
Published:2024-02-05
Contact:
Qinglin WANG
CLC Number:
Jie LIU, Yongzhen SHI, Bo YANG, Xiang ZHANG, Xinhai CHEN, Huajian ZHANG, Xiaowei GUO, Shengguo LI, Runhua LI, Jintao PENG, Tiaojie XIAO, Xuguang CHEN, Qingyang ZHANG, Biao LI, Can LENG, Yushui LI, Qinglin WANG. Parallel Algorithm Libraries for Tianhe Supercomputers[J]. Chinese Journal of Computational Physics, 2024, 41(1): 9-21.
Add to citation manager EndNote|Ris|BibTeX
URL: http://www.cjcp.org.cn/EN/10.19596/j.cnki.1001-246x.8784
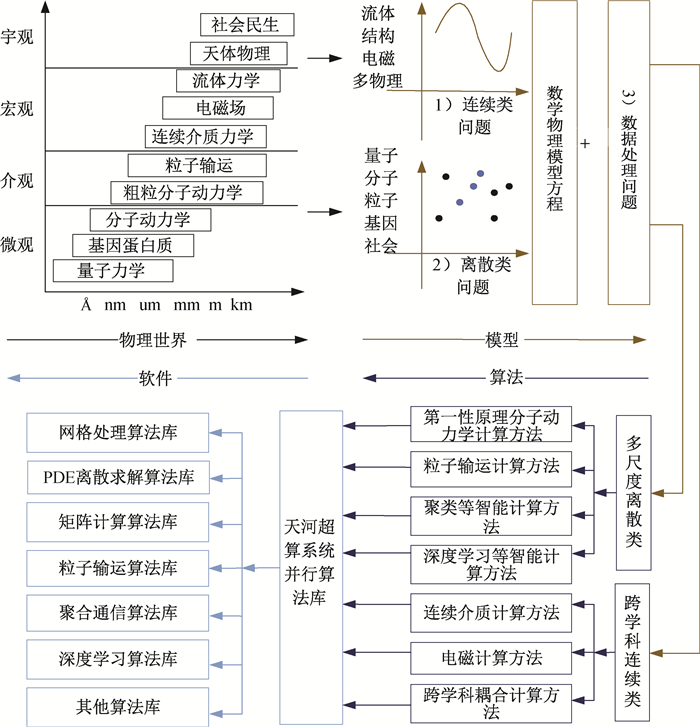
Fig.1 Parallel algorithm libraries on Tianhe supercomputers

Fig.2 Parallel mesh refinement of a U-shaped pipe using mesh processing library YH-GRID (a) initial coarse mesh; (b) respective mesh partitioning; (c) cross-section chart of the final refined mesh; (d) corresponding complete mesh information
| 规模/104 | 27 | 160 | 864.8 |
| 原始网格 |  |  |  |
| Greedy |  |  |  |
| RCM |  |  |  |
| CQ |  |  |  |
Table 1 Sparse matrixes produced by different reordering algorithms
| 规模/104 | 27 | 160 | 864.8 |
| 原始网格 | | | |
| Greedy | | | |
| RCM | | | |
| CQ | | | |
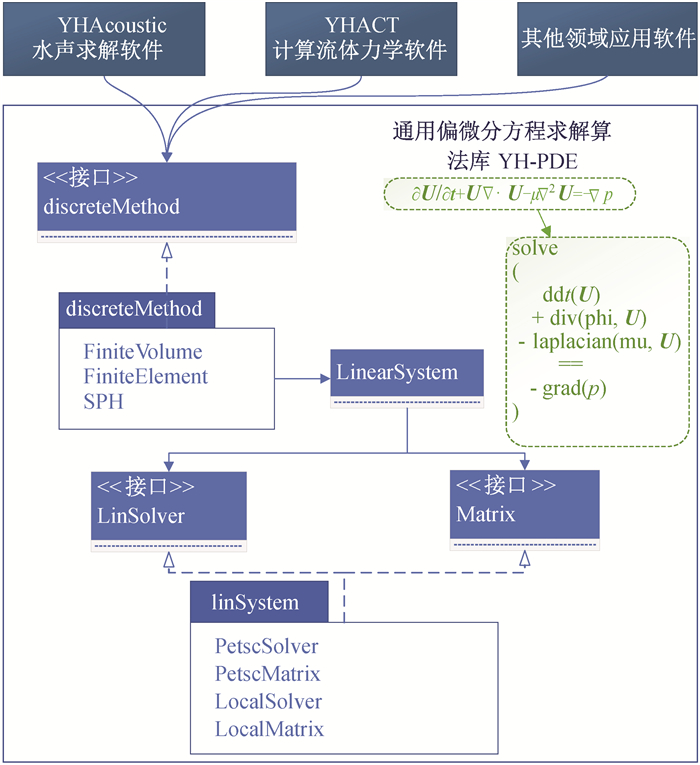
Fig.3 YH-PDE: General discrete solving library for partial differential equations
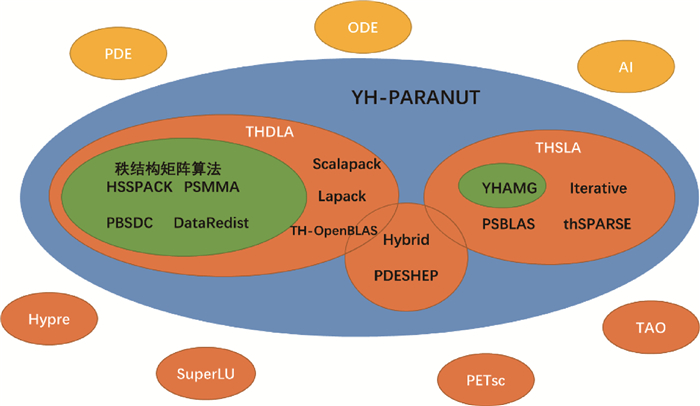
Fig.4 Architecture of matrix computing library YH-PARANUT

Fig.5 Architecture of particle transport library YH-PARTICLE

Fig.6 Main feature sets of collective communication library YH-CCL
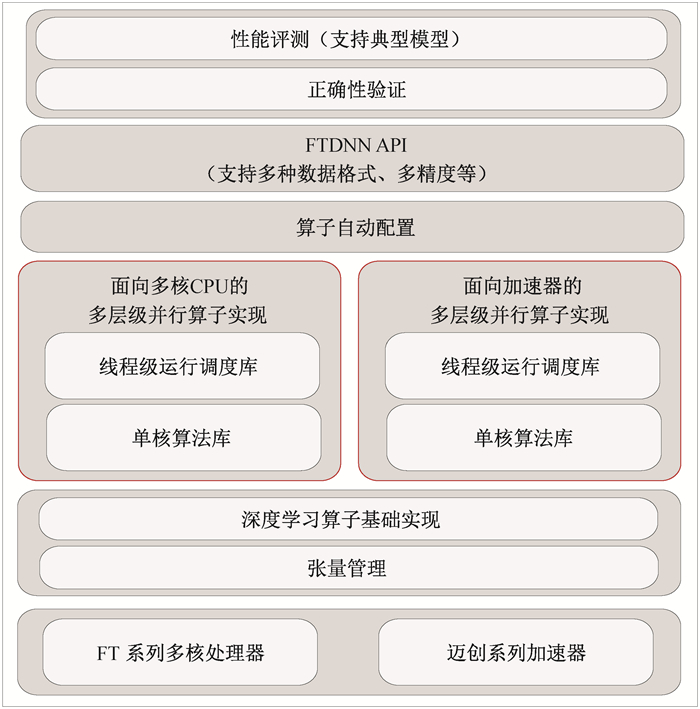
Fig.7 Architecture of deep learning library YH-DNN
| 1 |
YANG Xuejun , LIAO Xiangke , LU Kai , et al. The TianHe-1A supercomputer: Its hardware and software[J]. Journal of Computer Science and Technology, 2011, 26 (3): 344- 351.
DOI |
| 2 |
LIAO Xiangke , XIAO Liquan , YANG Canqun , et al. MilkyWay-2 supercomputer: System and application[J]. Frontiers of Computer Science, 2014, 8 (3): 345- 356.
DOI |
| 3 |
WANG Ruibo , LU Kai , CHEN Juan , et al. Brief introduction of TianHe exascale prototype system[J]. Tsinghua Science and Technology, 2021, 26 (3): 361- 369.
DOI |
| 4 |
高翔, 张翔, 徐传福, 等. 面向科学工程计算的通用网格生成软件系统研究[J]. 计算机工程与科学, 2020, 42 (10): 1897- 1904.
DOI |
| 5 |
DE COUGNY H L , SHEPHARD M S . Parallel refinement and coarsening of tetrahedral meshes[J]. International Journal for Numerical Methods in Engineering, 1999, 46 (7): 1101- 1125.
DOI |
| 6 |
CHEN Xinhai , GONG Chunye , LIU Jie , et al. A novel neural network approach for airfoil mesh quality evaluation[J]. Journal of Parallel and Distributed Computing, 2022, 164, 123- 132.
DOI |
| 7 |
CHEN Xinhai , LIU Jie , GONG Chunye , et al. MVE-Net: An automatic 3-D structured mesh validity evaluation framework using deep neural networks[J]. Computer Aided Design, 2021, 141, 103104.
DOI |
| 8 |
CHEN Xinhai , LIU Jie , PANG Yufei , et al. Developing a new mesh quality evaluation method based on convolutional neural network[J]. Engineering Applications of Computational Fluid Mechanics, 2020, 14 (1): 391- 400.
DOI |
| 9 | CHEN Xinhai, LIU Jie, GONG Chunye, et al. An airfoil mesh quality criterion using deep neural networks[C]//2020 12th International Conference on Advanced Computational Intelligence (ICACI). Dali, China: IEEE, 2020: 536-541. |
| 10 | CHEN Xinhai , GONG Chunye , WAN Qian , et al. Transfer learning for deep neural network-based partial differential equations solving[J]. Advances In Aerodynamics, 2021, 3 (1): 635- 648. |
| 11 |
CHEN Xinhai , LI Tiejun , WAN Qian , et al. MGNet: A novel differential mesh generation method based on unsupervised neural networks[J]. Engineering With Computers, 2022, 38 (5): 4409- 4421.
DOI |
| 12 |
ZHANG Huajian , GUO Xiaowei , LI Chao , et al. Accelerating FVM-based parallel fluid simulations with better grid renumbering methods[J]. Applied Sciences, 2022, 12 (15): 7603.
DOI |
| 13 | FARHAT C . A simple and efficient automatic fem domain decomposer[J]. Computers & Structures, 1988, 28 (5): 579- 602. |
| 14 | GEORGE J A . Computer implementation of the finite element method[M]. Stanford, CA: Stanford University, 1971. |
| 15 | ZHANG Yichen, LI Shengguo, YUAN Fan, et al. Memory-aware optimization for sequences of sparse matrix-vector multiplications[C]//2023 IEEE International Parallel and Distributed Processing Symposium (IPDPS). St. Petersburg, FL, USA: IEEE, 2023: 379-389. |
| 16 | YANG Xiaojian, LI Shengguo, YUAN Fan, et al. Optimizing multi-grid computation and parallelization on multi-cores[C]//Proceedings of the 37th International Conference on Supercomputing. Orlando, FL, USA: Association for Computing Machinery, 2023: 227-239. |
| 17 |
LI Shengguo , GU Ming , WU C J , et al. New efficient and robust HSS Cholesky factorization of SPD matrices[J]. SIAM Journal on Matrix Analysis and Applications, 2012, 33 (3): 886- 904.
DOI |
| 18 |
LI Shengguo , GU Ming , CHENG Lizhi . Fast structured LU factorization for nonsymmetric matrices[J]. Numerische Mathematik, 2014, 127 (1): 35- 55.
DOI |
| 19 |
LI Shengguo , LIAO Xiangke , LIU Jie , et al. New fast divide-and-conquer algorithms for the symmetric tridiagonal eigenvalue problem[J]. Numerical Linear Algebra with Applications, 2016, 23 (4): 656- 673.
DOI |
| 20 |
LI Shengguo , GU Ming , CHENG Lizhi , et al. An accelerated divide-and-conquer algorithm for the bidiagonal SVD problem[J]. SIAM Journal on Matrix Analysis and Applications, 2014, 35 (3): 1038- 1057.
DOI |
| 21 |
LIAO Xia , LI Shengguo , LU Yutong , et al. A parallel structured divide-and-conquer algorithm for symmetric tridiagonal eigenvalue problems[J]. IEEE Transactions on Parallel and Distributed Systems, 2021, 32 (2): 367- 378.
DOI |
| 22 |
LI Runhua , LIU Jie , ZHANG Guangchun , et al. An efficient heterogeneous parallel algorithm of the 3D MOC for multizone heterogeneous systems[J]. Computer Physics Communications, 2023, 292, 108806.
DOI |
| 23 | PENG Jintao, LIU Jie, DAI Yi, et al. Optimizing all-to-all collective communication on Tianhe supercomputer[C]//2022 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom). Melbourne, Australia: IEEE, 2022: 402-409. |
| 24 | WANG Qinglin, MEI Songzhu, LIU Jie, et al. Parallel convolution algorithm using implicit matrix multiplication on multi-core CPUs[C]//2019 International Joint Conference on Neural Networks (IJCNN). Budapest, Hungary: IEEE, 2019: 1-7. |
| 25 | 王庆林, 李东升, 梅松竹, 等. 面向飞腾多核处理器的Winograd快速卷积算法优化[J]. 计算机研究与发展, 2020, 57 (6): 1140- 1151. |
| 26 | WANG Qinglin, LI Dongsheng, HUANG Xiandong, et al. Optimizing FFT-based convolution on ARMv8 multi-core CPUs[C]//Euro-Par 2020: Parallel Processing: 26th International Conference on Parallel and Distributed Computing, Warsaw, Poland: Springer, 2020: 248-262. |
| 27 |
HUANG Xiandong , WANG Qinglin , LU Shuyu , et al. Evaluating FFT-based algorithms for strided convolutions on ARMv8 architectures[J]. Performance Evaluation, 2021, 152, 102248.
DOI |
| 28 | HAO Ruochen, WANG Qinglin, YIN Shangfei, et al. Towards effective depthwise convolutions on ARMv8 architecture[EB/OL]. (2022-06-24)[2023-06-05]. https://doi.org/10.48550/arXiv.2206.12124. |
| 29 | WANG Qinglin, LI Dongsheng, MEI Songzhu, et al. Optimizing one by one direct convolution on ARMv8 multi-core CPUs[C]//2020 IEEE International Conference on Joint Cloud Computing. Oxford, UK: IEEE, 2020: 43-47. |
| 30 | YIN Shangfei, WANG Qinglin, HAO Ruochen, et al. Optimizing irregular-shaped matrix-matrix multiplication on multi-core DSPs[C]//2022 IEEE International Conference on Cluster Computing (CLUSTER). Heidelberg, Germany: IEEE, 2022: 451-461. |
| 31 | 裴向东, 王庆林, 廖林玉, 等. 多核数字信号处理器并行矩阵转置算法优化[J]. 国防科技大学学报, 2023, 45 (1): 57- 66. |
| 32 |
郭晓威, 李超, 刘杰, 等. 一种高可扩展的通用CFD软件架构设计与原型系统实现[J]. 计算机工程与科学, 2020, 42 (12): 2117- 2124.
DOI |
| 33 |
XIAO Tiaojie , WANG Yun , HUANG Xiangyu , et al. Magnetotelluric responses of three-dimensional conductive and magnetic anisotropic anomalies[J]. Geophysical Prospecting, 2020, 68 (3): 1016- 1040.
DOI |
| 34 |
肖调杰, 周峰, 郑翾宇, 等. 大规模三维频率域电磁积分方程法数值模拟[J]. 计算机工程与科学, 2023, 45 (11): 1901- 1910.
DOI |
| 35 | 陈琳, 肖调杰, 刘剑, 等. 大地电磁一维磁化率、电阻率主轴各向异性正演[J]. 地球物理学进展, 2022, 37 (6): 2373- 2380. |
| 36 | ZHANG Qingyang, XU Lei, CHEN Rongliang, et al. Improving the performance of lattice Boltzmann method with pipelined algorithm on a heterogeneous multi-zone processor[C]//PDCAT 2022: Parallel and Distributed Computing, Applications and Technologies: 23rd International Conference, Sendai, Japan: Springer, 2023: 28-41. |
| 37 | LENG Can, TANG Zhuo, ZHOU Yige, et al. Fifth paradigm in science: A case study of an intelligence-driven material design[J/OL]. Engineering, 2023, 24: 126-137. |
| 38 |
YANG Xi , WANG Wei , MA Jinglun , et al. BioNet: A large-scale and heterogeneous biological network model for interaction prediction with graph convolution[J]. Briefings in Bioinformatics, 2022, 23 (1): bbab491.
DOI |
| 39 |
WU Chengkun , ZHANG Xiaochen , YANG Zhijiang , et al. Learning to SMILES: BAN-based strategies to improve latent representation learning from molecules[J]. Briefings in Bioinformatics, 2021, 22 (6): bbab327.
DOI |
| [1] | XU Xiaowen, MO Zeyao, HU Shaoliang, AN Hengbin. Feature-modified Algorithm Framework for Parallel Preconditioning in Sparse Linear Solvers [J]. Chinese Journal of Computational Physics, 2024, 41(1): 64-74. |
| [2] | Guoliang WANG, Bo ZHENG, Yueqiang SHANG. Parallel Finite Element Algorithms Based on Two-grid Discretizations for the Steady Navier-Stokes Equations with Damping Term [J]. Chinese Journal of Computational Physics, 2023, 40(5): 535-547. |
| [3] | Zhanhuang WANG, Bo ZHENG, Yueqiang SHANG. Parallel Two-level Stabilized Finite Element Algorithms for Unsteady Navier-Stokes Equations [J]. Chinese Journal of Computational Physics, 2023, 40(1): 14-28. |
| [4] | Xiaoyan HU, Zhengfeng FAN. An Efficient Parallel Algorithm on Multi-block Structure Meshes for Radiation Diffusion in Inertial Confinement Fusion Implosion [J]. Chinese Journal of Computational Physics, 2022, 39(3): 277-285. |
| [5] | Jiali ZHU, Yueqiang SHANG. A Parallel Two-level Stablized Finite Element Algorithm for Incompressible Flows [J]. Chinese Journal of Computational Physics, 2022, 39(3): 309-317. |
| [6] | DING Qi, SHANG Yueqiang. Parallel Finite Element Algorithms Based on Two-grid Discretization for Time-dependent Navier-Stokes Equations [J]. CHINESE JOURNAL OF COMPUTATIONAL PHYSICS, 2020, 37(1): 10-18. |
| [7] | ZHANG Shouhui, LIANG Dong. A Strang-type Alternating Segment Domain Decomposition Method for Two-dimensional Parabolic Equations [J]. CHINESE JOURNAL OF COMPUTATIONAL PHYSICS, 2018, 35(4): 413-428. |
| [8] | QI Meiling, YANG Qiong, WANG Canglong, TIAN Yuan, YANG Lei. Parallel Algorithm on GPU and Optimization for Molecular Dynamics Simulation of Irradiation Damage of Structure Materials [J]. CHINESE JOURNAL OF COMPUTATIONAL PHYSICS, 2017, 34(4): 461-467. |
| [9] | ZHANG Huifeng, OUYANG Jie, DAI Xiangyan. Parallel Algorithm for Brownian Configuration Fields with Finite Volume Method [J]. CHINESE JOURNAL OF COMPUTATIONAL PHYSICS, 2012, 29(1): 17-24. |
| [10] | SHANG Yueqiang, HE Yinnian. Parallel Finite Element Algorithms Based on Fully Overlapping Domain Decomposition for Time-dependent Navier-Stokes Equations [J]. CHINESE JOURNAL OF COMPUTATIONAL PHYSICS, 2011, 28(2): 181-187. |
| [11] | ZHANG Shouhui, WANG Wenqia. High-order Accurate Alternating Group 8-point Scheme for Convection Diffusion Problems [J]. CHINESE JOURNAL OF COMPUTATIONAL PHYSICS, 2009, 26(5): 703-711. |
| [12] | WU Jianping, SONG Junqiang, ZHANG Weimin, LI Xiaomei. Parallel Incomplete Factorization Preconditioning of Block Tridiagonal Linear Systems with 2-D Domain Decomposition [J]. CHINESE JOURNAL OF COMPUTATIONAL PHYSICS, 2009, 26(2): 191-199. |
| [13] | WU Jianping, SONG Junqiang, LI Xiaomei. Parallelization of Incomplete Factorization Preconditioning of Block Tridiagonal Linear Systems with 1-D Domain Decomposition [J]. CHINESE JOURNAL OF COMPUTATIONAL PHYSICS, 2008, 25(6): 673-682. |
| [14] | GUO Xiao-hu, ZHANG Lin-bo. Symmetric Super Compact Difference Scheme of the Navier-Stokes Equation and Its Parallel Algorithm [J]. CHINESE JOURNAL OF COMPUTATIONAL PHYSICS, 2006, 23(3): 281-289. |
| [15] | LIU Qing-kai, ZHANG Lin-bo. A Parallel Bisection Mesh Refinement Algorithm for Distributed Memory Parallel Computers [J]. CHINESE JOURNAL OF COMPUTATIONAL PHYSICS, 2005, 22(5): 399-406. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
Copyright © Chinese Journal of Computational Physics
E-mail: jswl@iapcm.ac.cn
Supported by Beijing Magtech Co., Ltd.