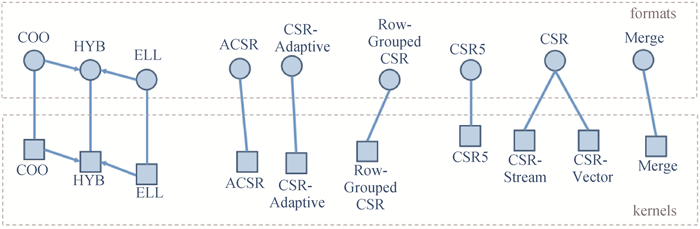
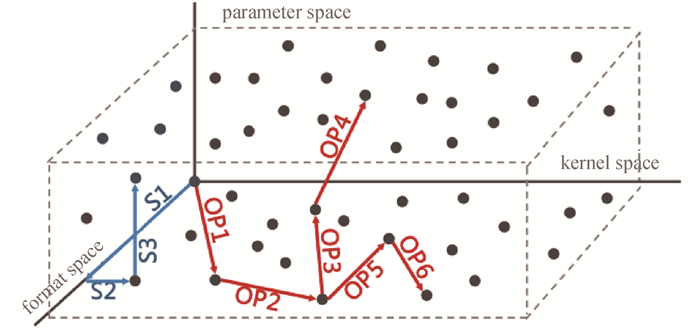
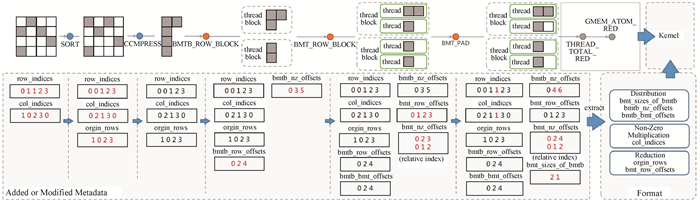
| 1 |
LANGR D , TVRDÍK P . Evaluation criteria for sparse matrix storage formats[J]. IEEE Transactions on Parallel and Distributed Systems, 2016, 27 (2): 428- 440.
|
| 2 |
FILIPPONE S , CARDELLINI V , BARBIERI D , et al. Sparse matrix-vector multiplication on GPGPUs[J]. ACM Transactions on Mathematical Software, 2017, 43 (4): 1- 49.
|
| 3 |
DAVIS T A , HU Yifan . The university of Florida sparse matrix collection[J]. ACM Transactions on Mathematical Software, 2011, 38 (1): 1- 25.
|
| 4 |
LI Jiajia, TAN Guangming, CHEN Mingyu, et al. SMAT: An input adaptive auto-tuner for sparse matrix-vector multiplication[C]//Proceedings of the 34th ACM SIGPLAN conference on Programming language design and implementation. Seattle, Washington, USA: Association for Computing Machinery, 2013: 117-126.
|
| 5 |
TAN Guangming , LIU Junhong , LI Jiajia . Design and implementation of adaptive SpMV library for multicore and many-core architecture[J]. ACM Transactions on Mathematical Software, 2018, 44 (4): 1- 25.
|
| 6 |
DU Zhen, LI Jiajia, WANG Yinshan, et al. AlphaSparse: Generating high performance SpMV codes directly from sparse matrices[C]//SC22: International Conference for High Performance Computing, Networking, Storage and Analysis. Dallas, TX, USA: IEEE, 2022: 1-15.
|
| 7 |
WANG Endong , ZHANG Qing , SHEN Bo , et al. High-performance computing on the Intel® Xeon Phi?: How to fully exploit MIC architectures[M]. Cham: Springer, 2014: 167- 188.
|
| 8 |
QUINLAN R. Data mining tools See5 and C5.0[EB/OL]. [2023-04-20]. https://www.rulequest.com/see5-info.html.
|
| 9 |
ASHARI A, SEDAGHATI N, EISENLOHR J, et al. Fast sparse matrix-vector multiplication on GPUs for graph applications[C]//SC'14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. New Orleans, LA, USA: IEEE, 2014: 781-792.
|
| 10 |
DAGA M, GREATHOUSE J L. Structural agnostic SpMV: Adapting CSR-adaptive for irregular matrices[C]//2015 IEEE 22nd International Conference on High Performance Computing (HiPC). Bengaluru, India: IEEE, 2015: 64-74.
|
| 11 |
GREATHOUSE J L, DAGA M. Efficient sparse matrix-vector multiplication on GPUs using the CSR storage format[C]//SC'14: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. New Orleans, LA, USA: IEEE, 2014: 769-780.
|
| 12 |
LIU Weifeng, VINTER B. CSR5: An efficient storage format for cross-platform sparse matrix-vector multiplication[C]//Proceedings of the 29th ACM on International Conference on Supercomputing. Newport Beach, California, USA: Association for Computing Machinery, 2015: 339-350.
|
| 13 |
MERRILL D, GARLAND M. Merge-based parallel sparse matrix-vector multiplication[C]//SC'16: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. Salt Lake City, UT, USA: IEEE, 2016: 678-689.
|
| 14 |
CHEN Tianqi, GUESTRIN C. XGBoost: A scalable tree boosting system[C]//Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco, California, USA: Association for Computing Machinery, 2016: 785-794.
|
| 15 |
ZHAO Yue, LI Jiajia, LIAO Chunhua, et al. Bridging the gap between deep learning and sparse matrix format selection[C]//Proceedings of the 23rd ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. Vienna, Austria: Association for Computing Machinery, 2018: 94-108.
|
| 16 |
BENATIA A , JI Weixing , WANG Yizhuo , et al. BestSF: A sparse meta-format for optimizing SpMV on GPU[J]. ACM Transactions on Architecture and Code Optimization, 2018, 15 (3): 1- 27.
|
| 17 |
CHEN Shizhao, FANG Jianbin, CHEN Donglin, et al. Adaptive optimization of sparse matrix-vector multiplication on emerging many-core architectures[C]//2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS). Exeter, UK: IEEE, 2018: 649-658.
|
| 18 |
SEDAGHATI N, MU Te, POUCHET L N, et al. Automatic selection of sparse matrix representation on GPUs[C]//Proceedings of the 29th ACM on International Conference on Supercomputing. Newport Beach, California, USA: Association for Computing Machinery, 2015: 99-108.
|
| 19 |
HOU Kaixi, FENG Wuchun, CHE Shuai. Auto-tuning strategies for parallelizing sparse matrix-vector (SpMV) multiplication on multi- and many-core processors[C]//2017 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). Lake Buena Vista, FL, USA: IEEE, 2017: 713-722.
|
 ), Guangming TAN2
), Guangming TAN2